Open Source Code
This website is still under construction - Please imagine that it is still the 1990s and this is Geocities...

The data is from Censys but I am searching and parsing it to look for HTTP 451 data specifically.
The Censys data includes details on HTTP servers, including the response code and response body that they return. I use the Censys API to automatically perform searches, for publicly accessible servers that are providing HTTP access and returning a response code of 451 gather daily statistics, and save copies of the fully HTTP response body.
If you would like to recreate your own version of this project, you will need to substitute in your own Censys API key. The number of queries that this series of scripts will perform will exceed the limit of the Censys free tier, so you will need to either request researcher-level access or subscribe to one of the paid tiers. Here are my estimates on the number of queries required by each individual script:
- Aggregate - 1
- Search - 70
- Bulk - 900
- Parse - 0
GitHub Repository
The code used to query and parse data from the Censys data is written in python. It is publicly available via GitHub for you to view, use, and remix in your own projects.
As a caveat, this is not great code by any imagination! I know just enough Python to be dangerous, but not enough to actually follow good coding practices or efficient methods. Please keep this large grain of salt in mind as you look over the code
Google Cloud Architecture
The scripts are set up to stash content in a Google Cloud Storage bucket. When running the scripts, you will need to have a service account configured in Google Cloud - you will also need to create an authentication key for the service account, and ensure that the account has the "Storage Admin" and "Pub/Sub Publisher" roles. Make sure that your environment has the GOOGLE_APPLICATION_CREDENTIALS variable set so that it knows to use this auth key.
If you are making your own version of these scripts, you will need to substitute the top of each file with the correct project-id and bucket-name that matches your Google Cloud project setup
I have tested the scripts running in Google Cloud Functions in the Python 3.9 runtime environment. The scripts each send a Pub/Sub notification to trigger the next script. The last two scripts are pretty beefy and pull a lot of data, so be sure to allocate enough memory for them to run!
- Aggregate (256MB)
- Search (256MB)
- Bulk (4GB)
- Parse (4GB)
Scheduling
I use Google Cloud Scheduler to trigger a Pub/Sub notification to start the first script (aggregate.py) on a regular basis. Currently, I have scheduled the series of scripts to run on Monday, Wednesday, and Friday.
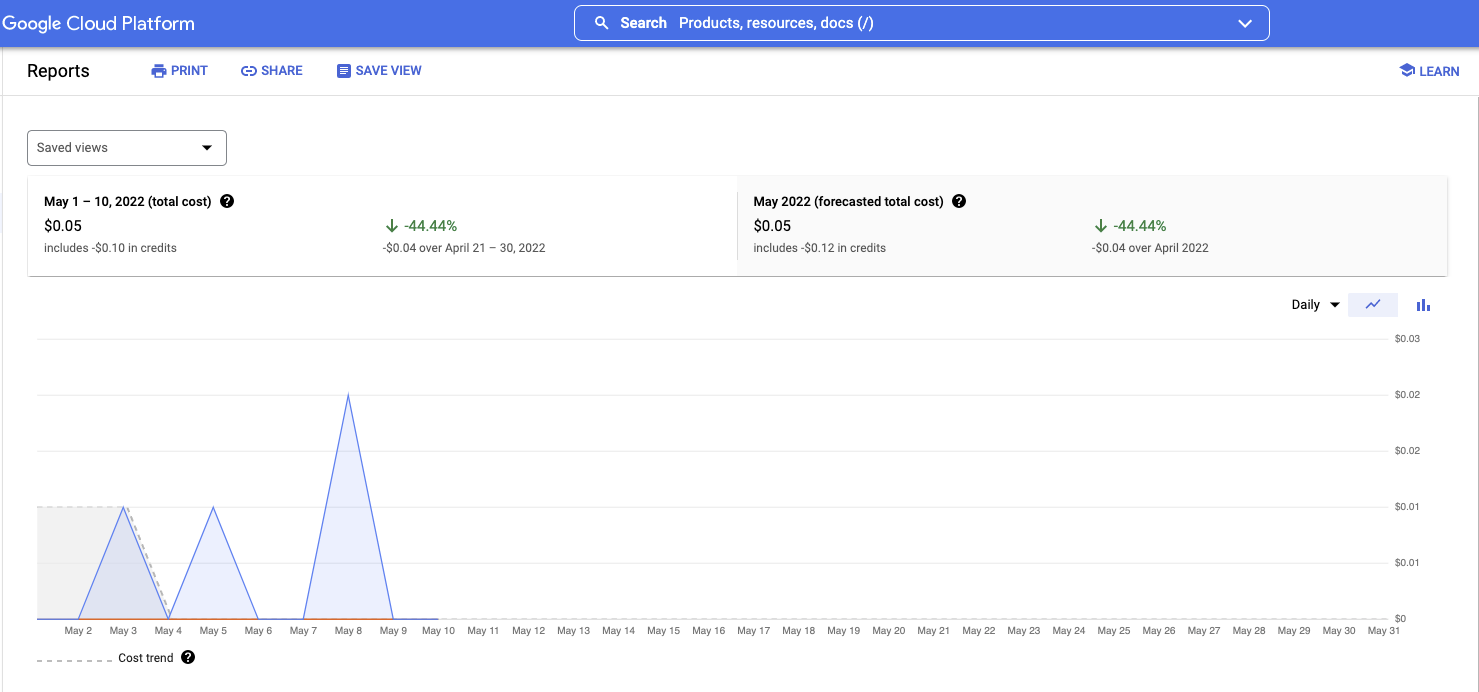
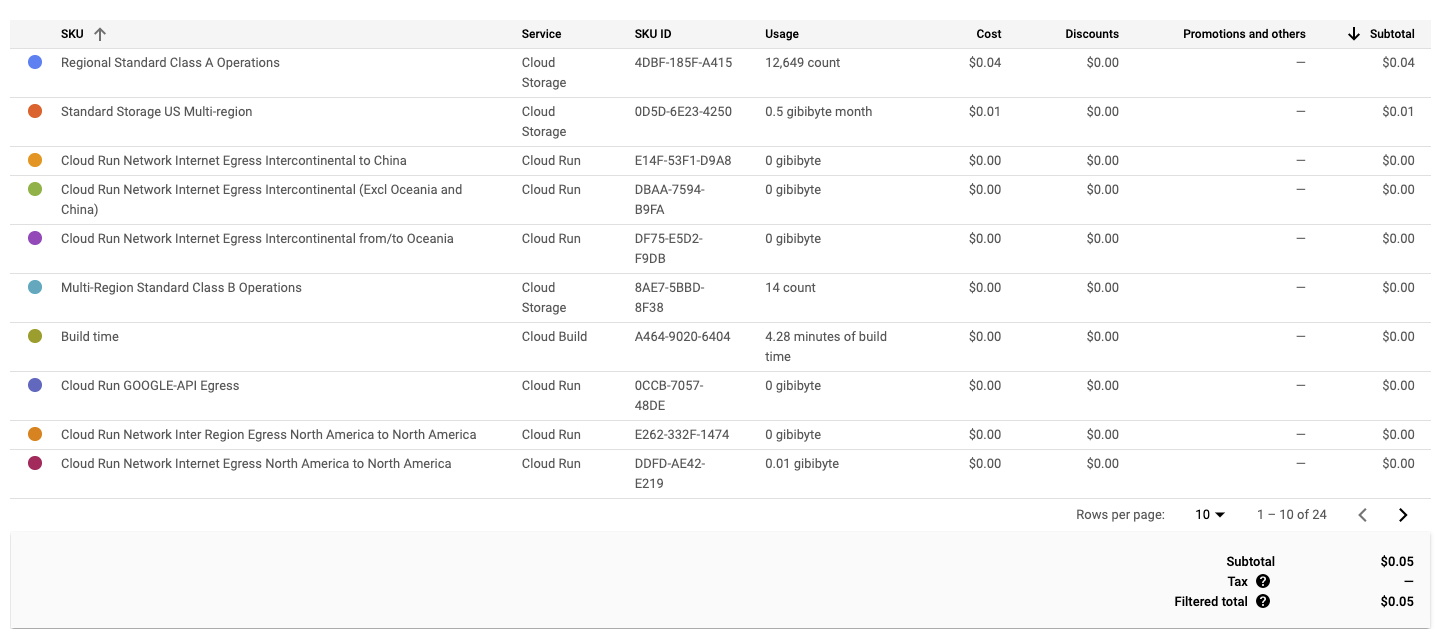
Costs
Because the scripts run only periodically, and only require a few minutes of active compute time, the total costs for this project are very low. Additionally, the data produced by the scripts are stored in a Google Cloud Storage bucket, which offers very affordable storage rates. However, the costs will gradually increase the longer the project runs. My plan is to eventually implement object lifecycles where only data from the current year is available in the Standard Tier, and older data is moved to the "Archive Class" - which is cheaper. This will also require me to re-work this website to display older data in a slightly different way.
Additionally, because the data is stored as simple static files - TXT, JSON, and CSV - there is no need to run a database. While this does somewhat limit my ability to query the data in dynamic ways, it does keep costs very low and manageable for my grad student budget. Anyone choosing to implement a similar structure in their own projects is encouraged to consider their own needs and whether a database will better serve their goals.